LLM Agents Are Breaking Your Platform, Not Your Architecture

LLM agents are flooding into prototypes, demos, and labs across the industry. If you’re a platform engineer, you’re likely fielding questions about whether these agents require new deployment paradigms, new monitoring strategies—or even full-blown architectural rewrites.
But after a year watching this space closely at Junction Labs, we’ve found the architecture is rarely the problem. The predominant "architecture of the 2020s" of frontend monolith with surrounding microservices and data platforms is fine. What breaks first is the platform: the tooling surfaces, guardrails, and runtime assumptions your systems rely on to stay observable, secure, and safe to iterate on.
That’s the immediate concern. But what about the long arc?
Agents could drive a transformation on the scale of the public cloud. Or, cynically, they could fade into the background like blockchain and web3. The most likely analogy, though, is mobile: a meaningful shift in how users interact with products, and how a slice of services gets built—but ultimately just one corner of the architecture that the platform has to enable.
This post isn’t about agent hype. It’s about what breaks when those agents move from playground to production—and what platform teams actually need to do about it.
Defining an LLM Agent
What exactly is an LLM agent? It’s less obvious than it sounds.
Just last week I read a blog post about building agents in Go. It links to an Anthropic article introducing "agentic systems." That article distinguishes between workflows and agents:
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
The core distinction is agency: does the model decide what to do next, or is it being told what to do by code? In practice, most agentic systems blur this line, and the term "agent" gets used for both.
With that in mind, David Crawshaw offers a better definition, although I'd enhance his diagram to be more explicit between the Agent and the LLM, and what else Agents can do beyond calling LLMs and tools:
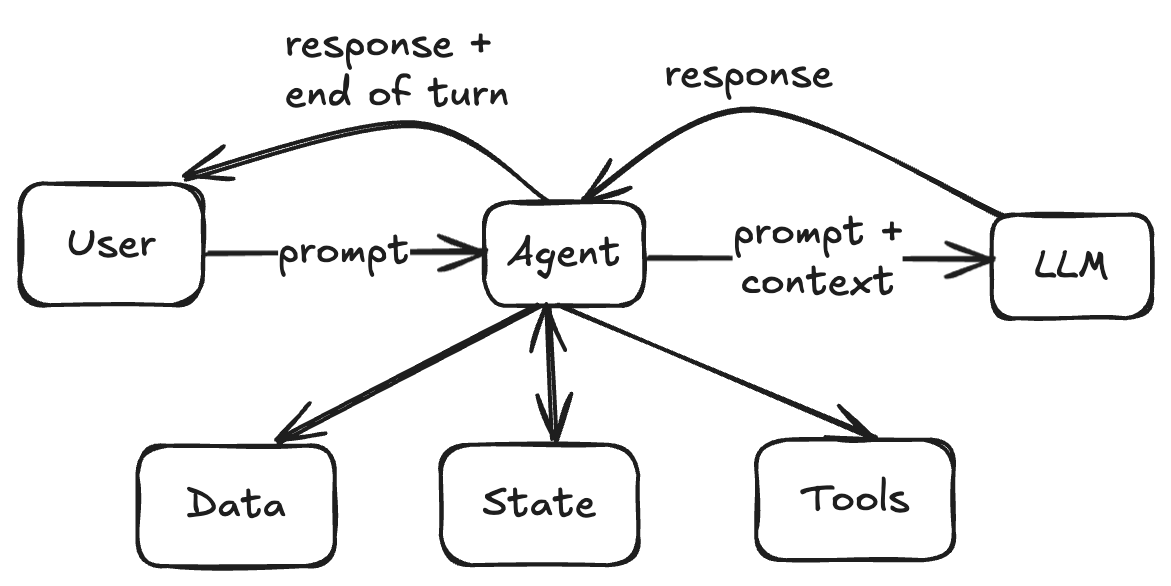
This framing makes it clear: agents aren’t a break from traditional service architecture. They’re built like any microservice—just with a probabilistic, text-driven core. The structure is familiar. The behavior is not.
What Will Break Your Current Platforms
Let's start with the hype-y things that aren’t new. Many of the "groundbreaking" capabilities attributed to LLM agents have been in production for years:
- Multi-step planning? Workflow engines and saga patterns.
- Learning and adaptation? Feature stores and real-time retraining.
- Autonomous decision-making? Recommenders and ML classifiers.
- Non-determinism? Bayesian systems have been making probabilistic decisions for decades.
But here’s what breaks your platform—observability, security enforcement, and execution flow—and why those parts need rethinking, even when your service architecture doesn’t.
The Observability Problem
Ask the same question twice—same hardware, same model—and get different answers. This isn't just ML variance. It's floating-point raciness, tokenizer drift, prompt sensitivity, and model implementation differences.
When a traditional service fails, you can replay the request and expect the same error. With agents, the same user input might lead to different tool calls or outputs depending on slight context changes.
Traditional observability tools fall short. Debugging an agent means tracing what it thought it was doing. You need semantic logs, intermediate reasoning traces, prompt versions, and retrieval state—logged in a structured, replayable format.
One engineering lead put it bluntly: "We had to overhaul our standard logging and tracing, adding verbose information around prompts, workflow steps, retrieval inputs, etc. Only then could we replicate production issues in staging."
This also affects deployment. Changing a single sentence in a system prompt can alter output formats or tool invocation patterns just as dramatically as a code change. Prompts are now business logic. You need versioning, rollback, and progressive delivery for them—just like you do for code.
The Security Problem
REST APIs give you schemas and strict contracts. Natural language removes those guardrails.
A user types: "Please delete all data tied to my account." What happens? The agent might call a deletion API, escalate to support, generate a compliance report—or all of the above. There’s no guaranteed interpretation.
Worse, agent outputs feel internal because they’re served from your infrastructure—but LLMs can be manipulated. Prompt injection can generate dangerous tool calls or leak internal data.
As much as we at Junction Labs advocate eliminating proxies where possible, here the opposite is true. You need a choke point—a gateway that inspects and controls traffic between agents and LLMs. LiteLLM is one emerging pattern: it logs, audits, and validates LLM generations before downstream consequences happen.
This isn’t just about security. It’s about reliability. It lets platform engineers apply model-level policies, catch regressions, and trace failures to generations, not just code.
Tool invocations must still be authz-validated, and sensitive values should come from verified context, not agent output. But adding a gateway between agent logic and the underlying model has become a necessary compromise.
The Execution Problem
By now, your agent teams have probably insisted on pulling in new frameworks—open source or vendor—to make their jobs easier. As a platform engineer, you might be skeptical: engineers love shiny tools. But in this case, they may actually have a point.
Historically, we’ve built software systems around two dominant modes:
- Interactive: Sub-second latency, stateless request/response. Think rendering Amazon.com.
- Batch: Multi-second to minutes, job-based and failure-tolerant. Think ensuring your Amazon order gets fulfilled and charged in the same transaction.
This split allowed most interactive microservices to remain stateless. The trick was offloading expensive logic—like machine learning driven personalization—into offline jobs, with their output loaded into online data stores.
LLM-backed agents break that contract.
Take OpenAI’s API: a few thousand tokens of context can mean 5–10 second response times. And you can’t just precompute answers—copilot suggestions, support flows, and tool interactions are all highly user- and context-specific. They live in an awkward middle ground: not quite batch, but no longer truly interactive.
This forces a rethink of execution infrastructure:
- Durable execution: If a call fails at second 8 of 10, do you retry the whole flow or resume from a checkpoint?
- Checkpointing: You may need to persist state between model calls, especially when tool outputs or human input are involved.
- Retry semantics: If the model reissues a tool call, is that action safe to repeat?
Workflow engines were built to handle this kind of thing—but they're usually clunky, with rigid logic and poor developer ergonomics. More importantly, they assume deterministic branching. LLM agents don’t. They generate logic on the fly, blurring planning and execution.
That’s why new stacks are gaining traction, some examples are:
- LangChain focuses on orchestration and chaining logic.
- Guardrails helps validate and constrain agent outputs at runtime.
- E2B explores execution environments purpose-built for LLM agents.
Each tackles a piece of the problem traditional workflow engines weren’t designed for.
Should you start rewriting your platforms?
Not yet. This is a general problem we cover in the platform engineering book, but this is a moment where many platform teams go wrong—not because they’re not forward-looking, but because they over-respond to not just the hype but also the real pressure from above (leadership) and from the side (product teams asking for golden paths, frameworks, or observability).
Here’s the reality:
- Right now, LLM agents should be a concern for a small subset of your systems—not a company-wide platform initiative.
- The tooling and best practices are changing too fast to justify locking in patterns or building foundational infrastructure.
- The shape of agents in your product will likely change dramatically over the next 6–12 months.
This is not the time for a second-system rewrite of your internal platform. It’s the time to:
- Secure the boundary: build safe interfaces between agents and tools.
- Enable safe exploration: give early adopters controlled freedom to move quickly, even if it’s messy.
- Enable your pioneers: support product teams pushing into agent territory without requiring broad buy-in or architectural commitment.
Yes, they will create some mess—that’s what pioneers do. But they’ll create far smaller messes than a centralized platform team betting on still-fluid technology to justify rebuilding their current platforms.
Think in terms of progressive enablement, not centralized abstraction.
Thanks to Rakesh Kothari (deductive.ai), Alex Clemmer (moment.dev), Conor Branagan, TR Jordan(tern.sh), Camille Fournier, and Marc Tremsal for their feedback on this post.
Subscribe to the Junction Blog
New blogs, product updates, events and more